Beginner's guide to what a reverse proxy is (educational)
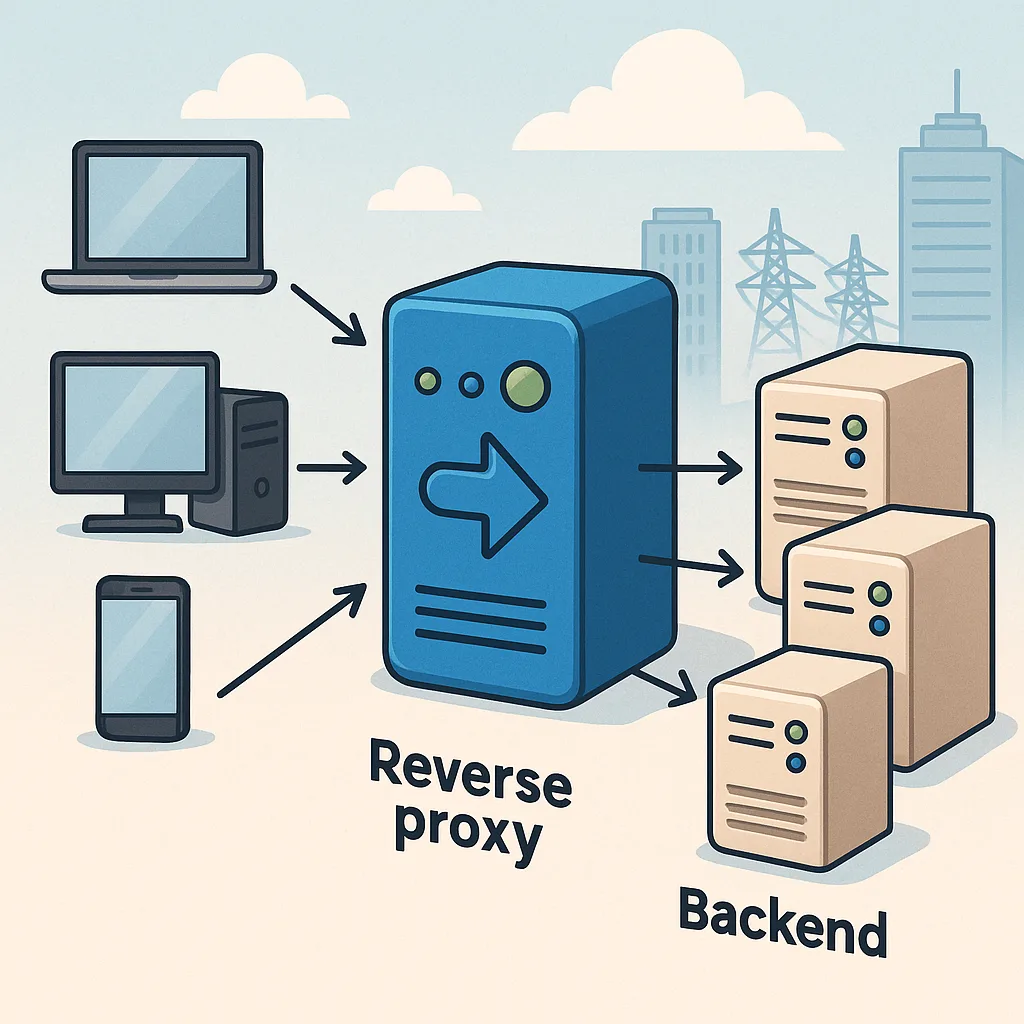
A reverse proxy is a server that sits between clients and one or more web servers, accepting incoming requests and forwarding them to the appropriate backend service on behalf of the client. It is different from a forward proxy, which represents the client to the wider internet, because a reverse proxy represents one or more servers to the clients. For someone new to infrastructure, think of a reverse proxy as a receptionist who directs visitors to the right department while keeping internal details private and simplifying access to multiple services.
At a basic level, a reverse proxy performs request routing, which means it decides where to send each incoming HTTP or HTTPS request based on rules you define. These rules can match request hostnames, paths, headers or other attributes, and they allow the proxy to deliver requests to different backend servers or containers. This makes it easy to host multiple applications behind a single public IP address and to change backend infrastructure without adjusting client-facing configuration.
Common functions of a reverse proxy include load balancing, SSL termination, caching and compression, and simple web application firewall features. Load balancing distributes requests across several backend servers to improve performance and resilience. SSL termination offloads the cost of handling TLS connections from backend servers by decrypting traffic at the proxy, which also simplifies certificate management. Caching and compression reduce response size and latency for repeated requests, improving user experience and reducing backend load.
- Load balancing to distribute traffic and improve availability.
- SSL/TLS termination to centralise certificate management and reduce backend complexity.
- HTTP caching and content compression to speed up responses and save bandwidth.
- Path- and host-based routing to expose multiple services on a single domain or IP address.
Practical deployments often use software such as Nginx, HAProxy or Traefik, or cloud provider load balancers that perform the same role. These tools can be placed at the network edge or inside a cluster and are commonly combined with container orchestrators and CI/CD pipelines. In a containerised environment, a reverse proxy can automatically route traffic to new service instances as they come online, which simplifies rollouts and scaling without requiring DNS changes or direct client awareness of backend topology.
From a security and operations perspective, a reverse proxy reduces exposure of backend servers by hiding their internal IP addresses and adding a single place to enforce access controls, rate limiting and logging. Centralised logging at the proxy makes it simpler to monitor traffic patterns and spot anomalies, although it is important to ensure that sensitive data is handled appropriately when logging. Administrators should also monitor performance and availability of the proxy itself, since it becomes a critical component of the service path and a single point that requires redundancy and testing.
Deciding whether to use a reverse proxy depends on needs such as traffic volume, complexity of services, and the desire for centralised TLS and routing. For simple sites with a single server, a reverse proxy may not be necessary, but for multiple services, microservices architectures, or when you want features like easy certificate renewal and sophisticated routing, a reverse proxy is very useful. For further Infrastructure-focused reading on this blog, see the posts under Infrastructure for related guides and practical examples. For more builds and experiments, visit my main RC projects page.
Comments
Post a Comment